[HOW]오라클 SQL, LAG(), LEAD(), FIRST_VALUE(), LAST_VALUE() 함수 사용하는 방법, ORACLE
Software/데이터베이스(SQL) 2020. 9. 25. 01:00안녕하세요. 신기한 연구소입니다.
이번 윈도우함수는 순서 관련 함수입니다.

LAG()
특정 컬럼을 설정합니다.
그리고 현재 행에서 특정 컬럼의 앞 몇 번째 행의 값을 가져오는 경우
LAG() 함수를 사용하면 됩니다.


기본으로 LAG()를 선택하면 현재 행의 바로 앞 행의 값을 가져옵니다.
그럼 옵션을 추가해보겠습니다.


옵션을 사용했습니다.
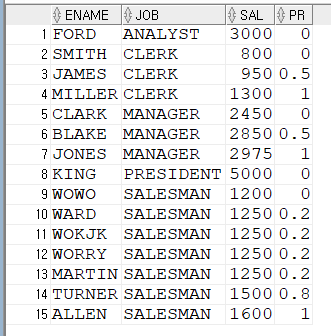
LAG(SAL, 4, 0)로 3개의 ARGUMENT인데 첫 번째는 가져올 행이며
두 번째 4는 현재 행부터 앞의 4번째 SAL 행의 값을 가져옵니다.
마지막 0의 의미는 다음과 같습니다.
4번째 앞의 행을 가져오는데 처음 행부터 4번째 행까지는
앞의 4번째 행이 존재하지 않아서 NULL이 됩니다.
이 경우 기본 값을 줄 수 있는데 세 번째 ARGUMENT가 그 역할을 합니다.
0으로 넣었으니 NULL 대신 기본값 0이 되었습니다.
LEAD()
이 함수는 앞 선 LAG() 반대 개념입니다.
선택된 현재 행의 바로 뒤의 값을 가져옵니다.


역시 옵션을 사용할 수 있습니다.
LAG와 같은 형식의 옵션입니다.


몇 번째 뒤의 행을 가져올 것인지와 NULL값에 대한 기본값을 정할 수 있습니다.
FRIST_VALUE
조건에 의해 가장 먼저 표출 된 값을 보여줍니다.


FIRST_VALUE(ENAME)는 ENAME을 입력했습니다.
소그룹은 JOB을 지정했습니다. (PARTITION BY JOB)
JOB별로 첫번째 값을 가져오고 있습니다.
LAST_VALUE()
조건에 의해 가장 나중에 나오는 값을 가져옵니다.


소그룹 JOB으로 묶은 뒤 JOB으로 정렬했습니다.
해당 그룹별로 마지막 ENAME이 조회됨을 알 수 있습니다.


ORDER BY를 넣지 않아도 사용이 가능합니다.
역시 마지막 ENAME을 가져옵니다.
현재 행 기준으로 앞 또는 뒤의 값을 가져오는
LAG()와 LEAD()가 있고
그룹 내 가장 첫 번째로 나오거나
가장 마지막으로 나오는 값을 검색할 수 있는
FRIST_VAL.UE()와 LAST_VALUE()에 대해 알아봤습니다.
잘못된 내용이나 수정이 필요한 부분이 있으면 댓글 주세요.
아래 하트(공감) 버튼을 눌러서 더 다양한 글을 쓸 수 있게 응원 부탁드립니다. 감사합니다.