


Spring Boot Gradle 프로젝트 생성하면 Toolchain download 오류 남. 해결 방법 공유. ToolchainDownloadFailedException
Software/Settings 2024. 12. 11. 07:00요즘 딥러닝과 파이썬만 공부하다 오랜만에 자바 스프링 한 번 해보려고 VSCode를 실행했다.
너무 오래되었는지 오류가 났다.

VSCode는 기존에 세팅 방식에서 변한 건 없고 jdk 버전만 올려주니 잘 되었다.
Spring.io에서 STS를 다운 받아서 실행하는데 오류가 난다.
오류메시지
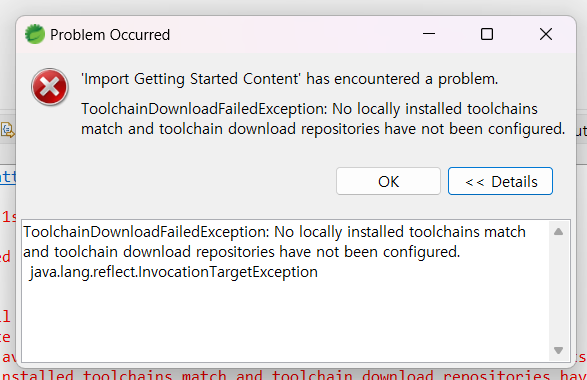
오늘 일자로 STS(이클립스 버전) 받았고 jdk17 버전으로 세팅했다.
Spring Web 프로젝트를 Gradle로 생성했다.
그러자 위 오류가 났다.
오류정보 : 'Import Gettiing Started Content' has encountered a problem. ToolchainDownloadFailedException: No locall installed toolchains match and toolchain download repositories have not been configured.
사실 첨 보는 오류였다.
오류 정보도 친절하지 않네. 어이구야.
같은 조건으로 Maven 프로젝트는 문제 없이 잘 된다.
Gradle에서 jdk 버전 체크를 하는 듯 다.
해결방법
jdk17, jdk19로 했더니 계속 오류가 났다.
오늘자로 받은 Spring STS는 최저 jdk 버전이 21부터 시작한다.
1. jdk21 버전을 다운 받는다. (https://jdk.java.net/archive/)
2. 원하는 위치에 압축을 푼다. (예: C:\jdk-21.0.2)
3. 환경설정에서 JAVA_HOME의 jdk 위치를 수정해서 넣어준다.

4. 명령 프롬프트에서 잘 세팅 되었는지 확인한다.

5. Spring STS를 실행하고 상단 Window>Preferences를 클릭한다.

6. Java>Compiler를 선택하고 JDK를 21로 변경 후 Apply(적용)한다.

7. Java>Installed JREs를 선택한 후 21 버전으로 선택 후 apply(적용)을 클릭한다.

8. Spring STS를 종료한다.
9. 원도우 탐색기를 실행해서 Spring STS가 설치된 위치로 이동한다.

10. SpringToolSuite4.ini 파일에 마우스 우클릭을 해서 메모장에서 편집을 클릭한다.
11. -vm을 찾고 그 아래 있던 정보는 지우고 새로 설치한 jdk위치를 포함한 아래 경로를 넣어주고 저장한다.

12. Spring STS를 다시 실행한다.
13. Spring Web Gradle 프로젝트를 생성한다.
이제 잘 실행될 것이다.
PS. SpringWeb 프로젝트를 생성했지만 Boot Dashboard의 local에 추가가 안되면 프로젝트 생성에 오류가 발생한 것이다.
프로젝트가 오류 없이 생성되면 아래와 같이 자동으로 프로젝트가 추가된다.

이번 포스팅에서 ToolchainDownloadFailedException: No locall installed toolchains match and toolchain download repositories have not been configured.
오류 해결방법에 대해 알아봤다.
삽질은 이제 그만...
'Software > Settings' 카테고리의 다른 글
| MinGW-w64에서 bin 폴더 없음? VSCode C/C++ 개발, MSYS2로 간단 해결! (최신 설치 방법), Visual Studio Code에서 C/C++ 세팅 방법 (0) | 2025.03.25 |
|---|---|
| [React 리액트] 리액트 개발환경 설치하는 방법. VSCode에서... (0) | 2023.07.30 |
| Vue.js (뷰3) 설치하는 방법. VSCode(비주얼스튜디오코드)에서 개발환경 세팅 설정. (0) | 2023.06.04 |
| Node.js 설치하는 방법. nodejs, 노드 with npm도 같이 (0) | 2023.05.21 |
| VSCode 설치하는 방법. (visual studio code, 비주얼 스튜디오 코드) (0) | 2023.05.20 |

