쉽게 풀어 쓴 딥러닝 손실함수 1 : 회귀 문제에서 오차제곱합(SSE), 평균제곱오차(MSE) 코딩하기.
인공지능(AI)/딥러닝(DeepLearning) 2025. 5. 14. 21:18딥러닝(Deeplearning)에서 손실 함수란?
딥러닝 스터디 중 손실 함수(loss function)를 알게 되었다.

머신러닝, 딥러닝에서 해당 모델의 성능을 평가할 사용하는 함수다.
모델이 예측, 인식한 값과 실제 값과의 오차를 알려준다.
손실 함수는 회귀와 분류 문제로 구분되어 있다.
용어도 어렵고 계산식도 한참을 봤다.
인공지능 학습이 쉽지 않을 거라 생각은 하고 있었다.
최대한 쉽게 이해하고 싶어 꼼꼼히 정리해 봤다.
손으로 숫자 5를 써서 딥러닝 학습을 통해 인식하고자 한다.
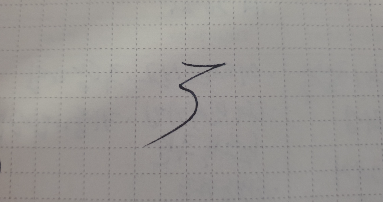
숫자 5를 썼지만 학습 결과 5일 확률이 0.3 정도 나왔다 가정하자.
1을 기준으로 무려 0.7을 잘못 인식했다는 결과다.
숫자 5인데도 손으로 쓴 글씨라 0.3 정도만 인식했다는 의미다.
무려 0.7을 잘못 인식했다고 알려줘야 한다.
인식률을 높여 숫자 5로 인식하게 알려줘야 한다.
바로 손실 함수가 그 역할을 한다.
즉, '얼마나 잘못 예측했나'를 수치로 보여주는 함수가 손실 함수다.
회귀 문제
과거 거래량, 과거 주가, 경제 전망 등을 활용해서 앞으로의 주가를 예측한다.
예측하는 주가는 입력값에 따라 결정된다.
입력값의 종류와 값 범위에 따라 결괏값이 결정된다는 의미다.
회귀는 결괏값이 연속적이라는 특징이 있다.
주가가 0 또는 1처럼 둘 중 하나값이 아니다.
이런 경우를 분류문제라고 한다. 0 또는 1.
회귀는 입력값이 따라 연속적인 금액값 중 하나가 종속된다.
이번 포스팅에서는 회귀 문제에 대한 손실 함수를 먼저 확인해 보자.
사실 용어만 봐서는 감이 안 잡힌다.
손실 함수 중 회귀 문제는 평균 제곱 오차(Mean Squared Error, MSE)와 오차 제곱 합(Sum of Squared Errors, SSE).
우선 이 2개의 함수를 확인해 보겠다.
평균 제곱 오차(Mean Squared Error, MSE)
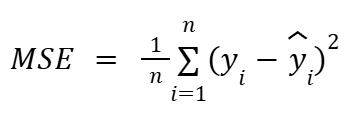
우와~ 어려운 식이 나타났다.
∑ (이하 시그마)를 처음 본다면 당황스러울 수 있다.
어렵지 않다.
시그마는 우측 식을 i=1부터 n까지 순서대로 대입한 값을 전부 더한다는 의미다.
간략하고 쉬운 식을 보자.
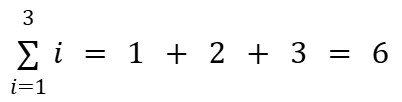
시그마 옆 i에 1부터 3까지 입력한다.
1 + 2 + 3으로 식이 만들어지고 결과는 6이 된다.
평균 제곱 오차(Mean Squared Error, MSE)의 경우는
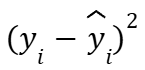
다음 식을 i=1부터 n번째까지 값들을 위 예제 식처럼 쭈욱 더한다는 의미다.
그리고 1/n으로 나누는 의미다. 0.5를 곱해도 된다.
식에 대한 설명을 했다.
이제 딥러닝에서 평균 제곱 오차(Mean Squared Error, MSE)를 사용하는 예를 들어보자.

3번 라인은 mean_squard_error함수로 평균 제곱 오차(Mean Squared Error, MSE)를 구현했다.
np.mean이 수식의 복잡한 평균을 쉽게 구해준다.
t는 true value로 6번 라인 index 4번째가 1이다.
y는 추측값을 가정해서 만들어 봤고 8번 라인 index 4번째가 0.7로 높은 확률이 나왔다.
함수를 실행하면 결과는 0.011500000000000003가 나온다.
정말 작은 수이다.
만약 true value는 그대로인데 17번 라인을 보면 index 4번째가 0.1로 낮은 확률이 나왔다.
그 결과 함수를 실행하면 결과는 0.1315으로 0.7로 나온 경우보다 높은 값이 나왔다.
결론은 결과가 낮을수록 오차가 적다는 의미로 볼 수 있다.
결괏값을 보고 오차를 조정하면 된다.
오차 제곱 합(Sum of Squared Errors, SSE)

(실제 값 - 예측 값)의 제곱을 2로 나눈 식이다.
약간 변형된 식을 보기도 한다.
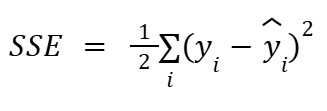
이 식은 시그마의 인수값이 다르다.
위 쪽에 인수값 n이 없고 아래 i만 있다.
i=1부터 n까지도 아니고 달랑 i 하나면 값을 하나만 받는다는 의미일까?
numpy.array를 실제값과 예측값에 할당하면 비록 배열 하나지만 내부의 많은 값을 활용할 수 있다.
예제 소스를 보자.

4번 라인의 식을 보면 np.sum을 사용했다.
합계 구하고 반으로 나눴다.
식은 심플하다.
7번 라인 t는 index 4번째 값이 1이다.
9번 라인 y는 index 4번째 값이 0.7로 높은 확률이다.
결과는 0.057500000000000016로 아주 작은 값이 나왔다.
그렇다면 오차가 크면 어떨까?
18번 라인 y는 index 2번째 값이 0.7이고 매칭되는 index 4는 0.1로 낮은 확률이다.
결과는 0.6575로 0.7보다는 꽤 큰 값이 나왔다.
마찬가지로 결과 값이 0에 가까워질수록 오차가 없어진다는 의미고,
결과 값이 0보다 커질수록 오차도 커진다는 의미다.
제곱이라 오차가 커질수록 더 큰 차이가 나타난다.
정리.
손실 함수 중 회귀 문제를 다루는 함수 2 종류를 확인했다.
평균 제곱 오차(Mean Squared Error, MSE)와 오차 제곱 합(Sum of Squared Errors, SSE) 두 함수다.
손실 함수로 출력 값으로 정확도와 오차를 확인할 수 있다.
그 값을 활용해 신경망 성능을 향상할 수 있다.
오차를 줄여서 정답에 가까워져라~~~
지금까지 손실 함수 중 회귀 문제에 대해 정리해 봤다.
잘못된 정보는 댓글 바란다.
'인공지능(AI) > 딥러닝(DeepLearning)' 카테고리의 다른 글
| [딥러닝]신경망 구현의 필수, 넘파이(Numpy)로 다차원배열(행렬) 활용하자. 왜? 어떻게? 사용 방법, 파이썬(Python)으로... (0) | 2025.04.11 |
|---|---|
| [딥러닝]신경망과 활성화 함수(계단 함수, 시그모이드 함수, ReLU 함수) 계산 방법. 초보용 핵심 정리. (0) | 2025.03.21 |
| [딥러닝] XOR 게이트와 다층 퍼셉트론으로 파이썬 코드 작성하는 방법 (0) | 2025.01.08 |
| [딥러닝]NAND, OR 게이트와 퍼셉트론 활용한 파이썬 코드 작성하는 방법, 인공지능 AI 초보 개발자 (0) | 2024.12.17 |
| [딥러닝]인공지능 초보 개발자면 퍼셉트론과 AND 게이트 활용 방법은 알고 가자, 쉬운 설명. (0) | 2024.12.10 |