

[HOW]SQL 데이터정렬, ROWNUM 사용하는 방법, ORDER BY, ROWNUM, ROWID -ORACLE(오라클)
Software/데이터베이스(SQL) 2020. 9. 10. 01:00안녕하세요. 신기한 연구소입니다.
SQL 개발을 하다 보면 전체 데이터 중 상위 몇 개만 조회하고 싶은 경우가 있습니다.
바로 이때 ROWNUM을 사용해서 순번을 정한 뒤 조건을 넣을 수 있는데요.
ROWNUM을 알기 위해서는 ROWID와 ORDER BY도 같이 알아보면 좋습니다.

우선 ROWID에 대해 알아봅니다.
테이블에 데이터를 입력하면 해당 행에 대해 ROWID를 생성합니다.
ROWID는 해당 행의 주소 값입니다.
모든 테이블의 행들은 각각의 고유한 주소 값을 가지고 있습니다.
즉, 이 ROWID를 알면 해당 행을 찾을 수 있다는 의미겠지요?
인덱스의 리프 블록(LEAF BLOCK)에는 인덱스 키 값과 그 인덱스에 해당하는 테이블의 행을 찾기 위한
해당 행의 ROWID를 포함하고 있습니다.

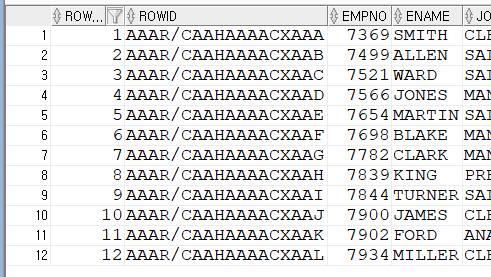
ROWNUM은 현재 조회한 쿼리에 순서 값을 나타냅니다.
1번부터 나타내는데 주의할 점이 있습니다.
다음 이미지를 살펴보세요.


처음 조회한 데이터는 ROWNUM 순번이 1번부터 순차적으로 나옵니다.
하지만 두 번째는 ENAME으로 ORDER BY를 적용했는데
ORDER BY 순서에 의해 ENAME은 정렬이 되었지만
ROWNUM은 순서대로 나오지 않습니다.
즉, ORDER BY 하기 전 조회된 데이터에 ROWNUM이 부여가 되고
그 뒤로 ORDER BY가 적용되기에 순번이 뒤섞여 나옵니다.
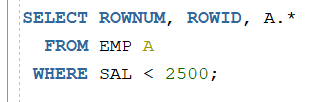



이 경우는 WHERE 조건을 명시했습니다.
조건에 맞게 조회를 하면서 ROWNUM이 순서대로 조회가 됩니다.
하지만 두번째 쿼리는 역시 ORDER BY에 맞게 SAL은 정렬이 되었지만
ROWNUM은 ORDER BY 하기 전에 순번이 적용되어서
또 뒤섞여 나오게 됩니다.
그렇다면 ORDER BY를 한 대로 ROWNUM을 적용하고 싶다면 방법이 있을까요?


이렇게 서브 쿼리(인라인 뷰)를 사용해서 미리 ORDER BY를 적용한 뒤
메인 쿼리에서 ROWNUM을 읽으면 미리 ORDER BY가 된 뒤로 순번을 정했기 때문에
ENAME도 정렬이 되었고 ROWNUM도 순서대로 순번이 붙어서 나오게 됩니다.
결론은
SQL문을 실행하면 실행 순서가 있습니다.
FROM 절에서 테이블을 확인하고
WHERE 절에서 조건에 맞는 데이터를 가공하고
GROUP BY 절에서 그룹핑하고
SELECT로 데이터를 출력합니다.
그리고 마지막으로 ORDER BY로 정렬을 하는데..
SELECT로 출력하는 시점에 ROWNUM을 적용하기에
그 이후 작업인 ORDER BY로 정렬을 하면 ROWNUM이 섞이게 되는 겁니다.
마지막으로 ORDER BY는 조회된 데이터를 정렬하는 경우 사용하는데
원하는 컬럼 1개 이상을 콤마(,)를 기준으로 나열하고
해당 컬럼마다 오름/내림 차순 설정을 하면 됩니다.
컬럼이 아닌 SELECT 절의 순서대로 숫자로 1, 2, 3으로 표시할 수도 있으며
ALIAS(별칭)을 사용해도 됩니다.


주의할 점은 테이블의 순서가 아닌 SELECT문의 순서를 사용합니다.


3가지 조건을 사용한 예제입니다.
주의할 점은 첫 번째 항목이 우선으로 정렬을 하고
첫번째 항목에 중복이 나오면 두 번째 항목을 기준으로 정렬합니다.
세 번째도 마찬가지고요. DESC는 역순을 의미합니다.


NM은 컬럼명이 아니고 SELECT문에서 ALIAS(별칭) 명입니다.
이렇게 ALIAS명으로 사용할 수 있습니다.
지금까지 ROWNUM, ROWID 그리고 ORDER BY에 대해 살펴봤습니다.
잘못된 내용이나 수정이 필요하면 댓글 주세요
아래 하트(공감) 버튼을 눌러서 더 다양한 글을 쓸 수 있게 응원 부탁드립니다. 감사합니다.


