[HOW]오라클 순위함수 사용하는 방법, 윈도우함수, RANK(), DENSE_RANK(), ROW_NUMBER() - ORACLE SQL
Software/데이터베이스(SQL) 2020. 9. 22. 01:00안녕하세요. 신기한 연구소입니다.
이번 포스팅은 윈도우함수(WINDOW FUNCTION) 중 순위함수에 대해 알아봅니다.
순위함수를 잘 사용한다면 다양한 그룹 데이터, 집계 데이터를 산출하는 경우
유용하게 사용할 수 있습니다.

그럼 윈도우함수 중 순위 함수는 어떤 것이 있는지 확인해보겠습니다.


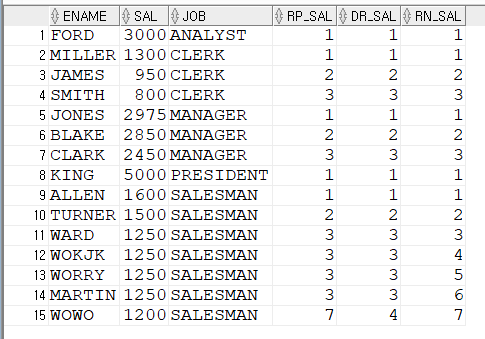
먼저 RANK() 함수를 알아봅니다.
위 쿼리를 보면 RANK() 함수를 사용하는 방법을 알 수 있습니다.
RANK() 함수는 OVER 내 옵션에서 ORDER BY를 필수로 사용하면서 특정 항목에 대한 순위를
정할 수 있습니다.
PARTITION BY의 여부에 따라 전체 순위를 정할지 아니면 특정 컬럼마다 순위를 정할지
결정할 수 있습니다.
R_SAL을 보면 1부터 SAL의 높은 금액순으로 순위를 정하고 있습니다.
특징은 같은 급여에 대해 같은 순위를 설정했습니다. 9위를 보세요.
그리고 그 다음은 10위가 아닌 같은 순위의 개수만큼 건너뛰고 14위가 나왔습니다.
DENSE_RANK()도 순위를 정하는 함수입니다.
마찬가지로 OVER 내 옵션으로 ORDER BY를 사용해야 합니다.
DR_SAL을 보면 RANK()와 다른 점을 찾을 수 있습니다.
같은 급여에 대해 같은 순위를 정하는 건 같지만
그다음 순위를 정할 때 같은 순위의 개수만큼 건너뛰지 않고 바로 다음 순위인
10위를 보여줍니다.
마지막 ROW_NUMBER()를 보면 이 또한 순위를 정하는 함수입니다.
사용법은 기존 RANK(), DENSE_RANK()와 같으며 결과는 RN_SAL을 보면
같은 급여와 상관없이 그냥 쭉~ 1위부터 순서를 정했습니다.
전체 데이터에 대한 순위를 정하는 방법에 대해 알아봤습니다.
이제 PARTITION BY 컬럼을 사용해서 소그룹 순위를 정해보겠습니다.

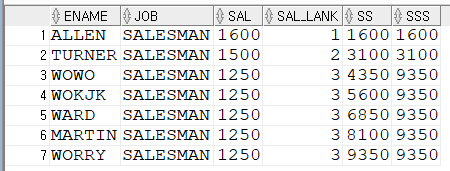
위 쿼리를 보면 2가지 다른 점이 있습니다.
먼저 PARTITION BY JOB이라는 옵션을 추가했습니다.
그리고 ORDER BY절에 JOB이 추가되었습니다.
JOB별로 정렬하고 JOB별로 순위를 정한다고 보면 됩니다.
RANK()를 보면 JOB별로 SAL 순위를 정했습니다.
마찬가지로 중복된 SAL에 대해서는 공동 순위를 정했습니다.
그리고 중복 순위 다음은 중복 개수만큼 건너뛰고 7위가 나왔습니다.
DENSE_RANK()도 같은 개념으로 보이는데
공동 순위 다음의 순위에 대한 개념만 다릅니다.
중복 개수가 있어도 바로 다음 순위 4위를 보여줍니다.
마지막 ROW_NUMBER()도 JOB별로 순위를 정했는데
SAL 금액이 같아도 공동 순위 없이 순위를 정하고 있습니다.
오라클 윈도우함수에서 순위 함수에 대해 알아봤는데요.
이제는 RANK(), DENSE_RANK, ROW_NUMBER() 함수가 나와도
문제없이 사용할 수 있다고 생각됩니다.
윈도우함수는 SELECT문에서만 사용할 수 있다는 것은 잊지 마세요.
잘못된 내용이나 수정이 필요하면 댓글 주세요.
아래 하트(공감) 버튼을 눌러서 더 다양한 글을 쓸 수 있게 응원 부탁드립니다. 감사합니다.