[HOW]오라클(ORACLE) 비율함수 사용하는 방법, 윈도우함수, NTILE(), RATIO_TO_REPORT(), PERCENT_RANK(), CUME_DIST()
Software/데이터베이스(SQL) 2020. 9. 24. 01:00안녕하세요. 신기한 연구소입니다.
데이터를 조회한 후 결과를 가지고 비율을 정해서 사용하고 싶다면
윈도우함수의 비율함수를 사용하면 됩니다.

NTILE()
전체 조회된 데이터를 순차적으로 나열한 뒤 원하는 수만큼의 그룹으로 나눌 수 있습니다.


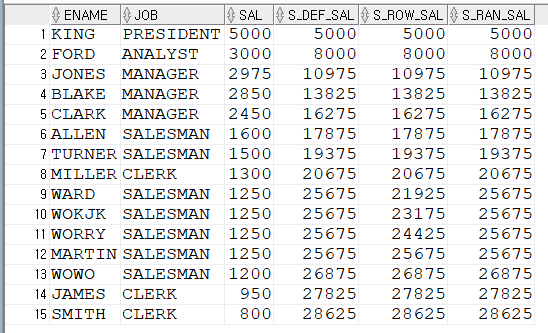
위 쿼리의 결과를 보겠습니다.
NTILE(3)으로 ARGUMENT를 3을 입력했습니다.
JOB을 GROUP BY 해서 JOB별로 OVER (ORDER BY SUM(SAL) DESC)
즉, SUM(SAL)로 역순 정렬하게 했습니다.
결과는 GD에 순번이 3으로 3개 그룹으로 나누었습니다.
1, 2는 2개 3은 1개입니다.
그룹을 정할 때 딱 나눠지지 않으면 1순위부터 1개씩 더 추가하는 방식으로
그룹이 정해집니다.
총 5개 결과를 3개 그룹으로 묶어야 하니 2개가 남게 됩니다.
그래서 1위에 1개 2위에 1개씩 추가했습니다.


이번에는 5개씩 나눴습니다. 남는 게 없으니 딱 맞게 하나씩 정해졌네요.


이번에는 GROUP BY를 사용하지 않고 총 15건 중 7개의 그룹으로 나눴습니다.
15개니 1개가 남아서 1위에 하나 더 추가되었네요.
이렇게 결과에 대해 균등하게 그룹 순번을 표현하고 싶을 때 NTILE()을 사용하면
딱 좋겠네요..
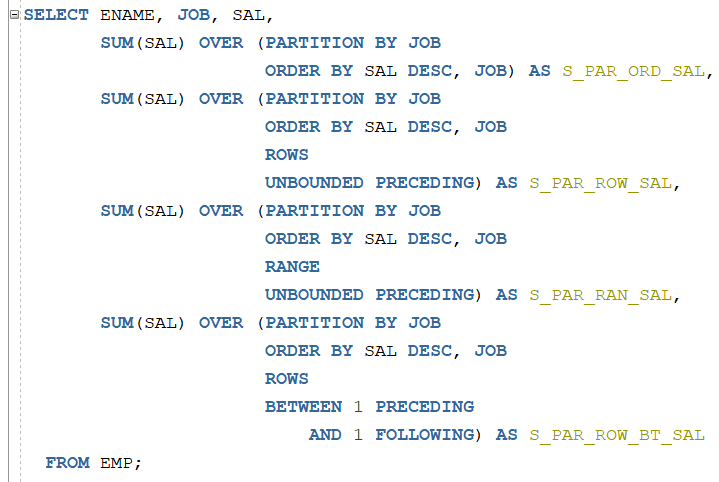
RATIO_TO_REPORT()
선택한 컬럼의 전체 합을 구한 뒤 해당 컬럼 하나의 값마다 전체 합에 대한 비율을
보여주는 함수입니다.
만약 총 합계가 10000이고 첫 번째 행이 1000이면 0.1이 되겠네요..


위 쿼리의 결과를 보겠습니다.
먼저 SU를 보면 COMM의 총합을 표현하고 있습니다.
WSUM은 COMM을 총 합인 SU로 나눈 백분율을 소수점으로 나타내고 있습니다.
RTR을 보면 RATIO_TO_REPORT를 사용했는데 같은 결과가 같습니다.
선택된 컬럼의 전체 합에 대해 각 행의 백분율을 소수점으로 표현하는
함수이니 잘 활용하세요.
PERCENT_RANK()
PARITION BY로 소그룹을 지정한 컬럼을 기준으로 첫 컬럼은 0이고
마지막 컬럼은 1이 됩니다.
그리고 그 사이의 컬럼은 비율대로 소수점으로 표현하게 됩니다.
예를 들어 소그룹에 대한 행이 3건이라면
첫번째 행은 0 두번째 행은 0.5 세 번째 행은 1의 결과를 보여줍니다.

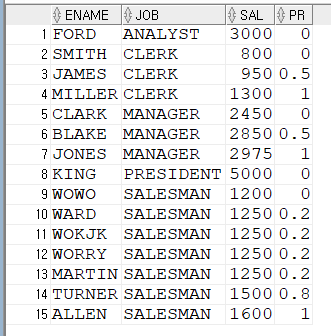
위 쿼리의 결과를 보겠습니다.
JOB별로 PERCENT_RANK를 구해봤습니다.
JOB을 보면 ANALYST는 1건이라 PR이 0입니다.
CLERK는 3건이라 0/0.5/1이 순서대로 나왔습니다.
SALESMAN의 경우 7건입니다.
첫번째는 0이고 마지막은 1인데 가운데 0.2가 4건, 0.8이 1건 나왔습니다.
중복된 값은 같은 비율을 표현하고 있네요. 참고하세요.
CUME_DIST()
이 함수는 PERCENT_RANK()와 비슷한 듯 다릅니다.


JOB을 그룹 조건으로 (PARTITION BY JOB) SAL 역순으로 조회했습니다.
CLERK를 보면 마지막 SAL은 800입니다.
마지막 값을 기준으로 앞으로 백분율을 표시합니다.
즉 800이 1이 되고 비율로 0.67/0.33이 조회되었습니다.
SALESMAN은 중복된 값이 있어서 0.86으로 같은 값이 조회되었네요.


SAL을 순정렬 했습니다.
이제는 CLERK의 1300 값이 1이 되었습니다.


JOB에 대한 소그룹이 아닌 전체에 대해 조회해 봤습니다.
이제 이해가 잘 되시나요?
지금까지 윈도우함수 중 비율함수에 대해 살펴봤습니다.
잘못된 정보나 수정이 필요하면 댓글 주세요.
아래 하트(공감) 버튼을 눌러서 더 다양한 글을 쓸 수 있게 응원 부탁드립니다. 감사합니다.