


[HOW]SQL 그룹 함수(ROLLUP, CUBE, GROUPING, GROUPING SETS) 사용하는 방법, 오라클(ORACLE)
Software/데이터베이스(SQL) 2020. 9. 20. 01:00안녕하세요. 신기한 연구소입니다.
이번 포스팅은 그룹핑에서 유용하게 사용할 수 있는 함수들을 알아봅니다.

기본적으로 GROUP BY를 사용해서 데이터를 그룹핑하는 방법은 기존 포스팅에서
같이 알아봤습니다.
그 그룹핑된 결과를 그룹별로 소계, 총계를 구할 수 있는 함수가 있는데요.
바로 ROLLUP과 CUBE입니다.
ROLLUP 함수
ROLLUP 함수는 조건 컬럼의 중간 소계와 총합계를 만들어주는 함수입니다.
이렇게 멋진 함수가 있었다니..ㅎㅎㅎ


보통 이런 쿼리를 이용해서 그룹핑합니다.
하지만 동호회를 그룹핑해서 JOB의 소계를 구하고
전체 합계를 구하려면 별도로 쿼리를 작성해서 UNION 같은
연산자를 사용하거나 서브 쿼리를 사용하는 방법을 사용할 수 있지만
그렇게 만들면 점점 복잡해지고 쿼리양도 많아집니다.
ROLLUP 이미지
이런 경우 ROLLUP을 사용해서 편리하게 소계와 총계를 구할 수 있습니다.
GROUP BY 다음에 ROLLUP을 추가하고 소계와 총계를 원하는
컬럼을 구성하면 됩니다.
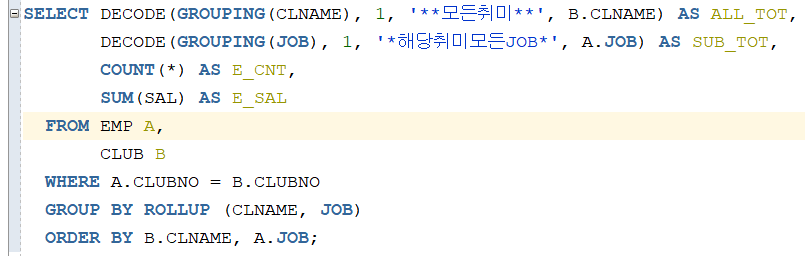

GROUP BY에서 컬럼의 구성에 따라 소계와 총계의 개념이 달라집니다.


컬럼이 많아지면 소계도 단계별로 생성됩니다.
CUBE 함수
CUBE 함수는 그룹핑한 컬럼에 대해 소계를 만드는데
설정한 컬럼에 대해 각각 소계를 보여주고 총계를 보여줍니다.


JOB에 대한 소계도 잘 표출하고 있습니다.
GROUPING SETS 함수
CLNAME 과 JOB에 대해 각각 소계를 구할 수도 있습니다.


GROUPING SETS에 CLNAME 과 JOB 컬럼을 사용하면
CLNAME에 해당하는 모든 취미의 합과
JOB에 해당하는 모든 취미에 대한 합을 보여줍니다.
집계 데이터를 가지고 원하는 컬럼에 대해 소계를 구하는데 제격이네요.
GROUPING 함수
지금까지 3가지 그룹 관련 함수를 확인했습니다.
해당 쿼리를 보면 SELECT문에 GROUING 함수를 볼 수 있습니다.
GROUPING 함수는 GROUP BY에 설정된 컬럼을 ARGUMENT로 넣은 경우
합계를 나타내는 행이 나오는 경우 결과로 1을 보여줍니다.
일반 합계는 0 해당 컬럼에 소계(총계)가 나오는 경우 1을 리턴합니다.
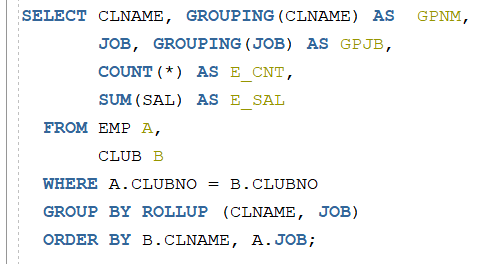

이제 이 4가지 그룹 함수를 가지고
개발하면서 멋진 그룹 쿼리를 만들어 볼 수 있겠네요.
잘못된 정보나 수정이 필요하면 댓글 주세요.
아래 하트(공감) 버튼을 눌러서 더 다양한 글을 쓸 수 있게 응원 부탁드립니다. 감사합니다.
'Software > 데이터베이스(SQL)' 카테고리의 다른 글
| [HOW]오라클 순위함수 사용하는 방법, 윈도우함수, RANK(), DENSE_RANK(), ROW_NUMBER() - ORACLE SQL (0) | 2020.09.22 |
|---|---|
| [HOW]오라클 윈도우함수(분석함수) 기본 사용하는 방법, ORACLE WINDOW FUNCTION, UNBOUNDED PRECEDING FOLLOWING CURRENT ROW ROWS RANGE (1) | 2020.09.21 |
| [HOW]SQL 서브쿼리 다양하게 사용하는 방법, 스칼라, 인라인 뷰, 중첩, 오라클(ORACLE) (0) | 2020.09.19 |
| [HOW]SQL EXISTS와 LIKE 검색 조건 사용하는 방법 (0) | 2020.09.18 |
| [HOW]SQL 조건 중 IN (A, B, C, ...) 사용하는 방법 (0) | 2020.09.17 |













