딥러닝 신경망 스터디 중 MNIST 데이터셋을 만났다.
그리고 파이썬 피클(python pickle)이 나타났다.

MNIST 데이터셋
인공지능 머신러닝 분야에서 유명한 데이터셋이라고 한다.
손으로 쓴 숫자에 대한 인식에 필요한 필수 자료라고 한다.
딥러닝 실습은 해당 이미지와 데이터를 다운 받아야 한다.
전부터 유명한 사이트에 가서 다운로드를 시도했다.
그런데 파일이 없다.
gz파일 4개를 다운받아야 하는데 없다.
다행히도 Apache SystemDB 사이트에서 찾았다.
오픈 소스 머신러닝 시스템에 대한 사이트로 해당 파일을 다운로드할 수 있다.

위 파일에 손으로 쓴 숫자에 대한 인식 테스트를 할 수 있는 데이터가 있다.
혼련 이미지 6만 장과 시험 이미지 1만 장이 포함되어 있다고 한다.
그렇다면 딥러닝 신경망을 위한 4개의 gz 파일은 어떻게 사용할까?
파이썬(Python)에서 직렬화(Serialization)를 지원하는 pickle(피클)이 있다.
4개의 gz 파일들은 피클링(직렬화)으로 하나의 피클(pickle) 파일로 만들면 된다.
1개로 만들어진 직렬화된 pickle 파일을 파이썬(Python)으로 쉽게 사용할 수 있다.
pickle 파일?
정의를 살펴보면 파이썬(python)에서만 사용하고 객체 직렬화를 하는 모듈이라고 한다.
피클링을 직렬화라고도 하는데 직렬화(serialization)는 또 무엇인가?
직렬화(Serialization)
프로그램을 실행하면 컴퓨터 메모리에 저장되고 사용된다.
컴퓨터 메모리는 전원을 끄면 사라지는 휘발성 공간이다.
메모리에 저장된 데이터, 객체를 별도로 저장하거나 다른 시스템에 보내는 경우가 있다.
컴퓨터 메모리 특성상 영구 저장이나 다른 시스템에 공유가 안된다.
꺼내서 저장하거나 전달해야 한다.
저장하거나 전달할 때 특정 형식이 필요하다. 예를 들어 바이너리, 스트림 형식.
바로 이런 형식으로 변환하는 과정을 직렬화라고 한다.
다시 사용할 수 있게 만드는 과정은 역 직렬화라고 한다.
요즘 많이 사용하는 JSON도 직렬화의 하나다.
이게 무슨 말인가? 싶기도 하다.
나도 처음 자바(java)에서 직렬화를 보고 이해하는데 시간이 좀 걸렸었다.
이해하기 쉽게 예를 들어보자.
가구 전시장에 있는 전시된 장롱을 할인받아 구매했다. (데이터 구조, 객체)
크기가 너무 커서 일단 분해해서 배송을 한다. (피클링, 직렬화)
집에 도착해서 다시 조립한다. (역 피클링)
이런 느낌?
파이썬 전용 직렬화, 피클 (pickle)
파이썬(python)과 넘파이(numpy)에서 사용하는 배열, 튜플 그리고 클래스 객체.
이렇게 데이터 구조와 객체를 별도 파일에 저장할 때 필요하다.
마찬가지로 파이썬 데이터 구조나 객체를 저장하고 전송하고 싶다면 그대로는 안된다.
이동할 수 있는 형태로 변환해 주는 직렬화( Serialization ), 피클이 필요하다.
파이썬 피클(python pickle)은 바이너리 형태로 저장된다.
그래서 파일을 메모장에 열어도 알 수 없는 문자로 가득할 것이다.
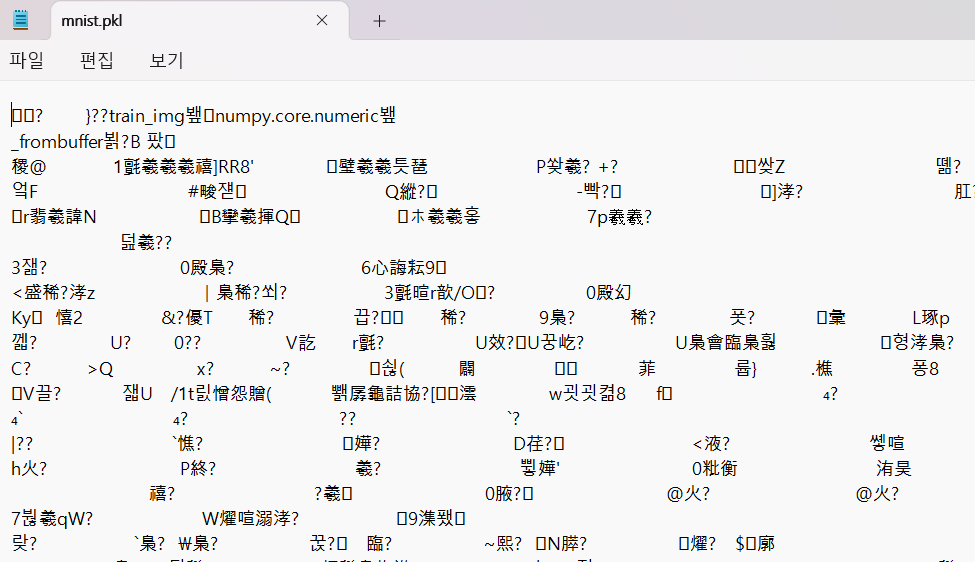
이렇게 변환된 데이터는 파일로 저장하거나 메모리 또는 데이터베이스(DB)에 전달 가능하다.
저장하거나 보냈다면,
다시 꺼내 사용하거나 네트워크로 받았다면 원래 상태로 변환해서 사용해야 한다.
다시 말해 피클링(직렬화)으로 저장한 데이터를 시스템에서 사용하기 위해 다시 역 피클링한다는 의미다.
MNIST 데이터셋에 피클(직렬화)이 왜 필요하지?
MNIST 데이터셋을 사용하게 위해 성격이 다른 4개의 gz 파일을 받았다.
프로그램에서 사용하기 위해서는 매번 압축도 풀고 4개의 파일을 컨트롤해야 한다.
4개의 파일을 데이터셋 형태로 하나의 피클(pickle)에 저장하면 속도도 빠르다.
또한 파일로 저장해서 언제든 꺼내 사용할 수 있다.
인공지능 머신러닝, 딥러닝의 학습용 실습을 위해서 피클(pickle)은 기본이다.
피클링과 역 피클링 예제.
파이썬 피클(Python pickle)로 파일을 만들고 사용하는 방법을 보자.
import pickle
my_data = {'이름':'나쉐프', '나이':40, '소모품':['도마','칼','접시']}
#my_data 피클 파일을 dump로 생성.
with open('my_data.pkl', 'wb') as f:
pickle.dump(my_data, f, -1)
print('my_data.pkl이 생성되었다')
file_path = './my_data.pkl'
try:
with open(file_path, 'rb') as rf:
get_data = pickle.load(rf)
#my_data 피클 파일을 다시 읽기.
print('get data : ', get_data)
except FileNotFoundError:
print(f"오류: '{file_path}' 파일을 찾을 수 없다.")
except Exception as e:
print(f"오류발생 : {e}")
'''
실행결과
my_data.pkl이 생성되었다
get data : {'이름': '나쉐프', '나이': 40, '소모품': ['도마', '칼', '접시']}
'''윈도우 탐색기로 로컬 폴더를 보면 pkl 확장자 파일이 생성됨을 볼 수 있다.
이 파일을 다시 load 하면 저장한 데이터가 그대로 출력된다.
pickle 모듈은 안전하지 않다.
이건 뭔 소린가?
파이썬(python) 사이트에서 pickle를 찾아보면 다음과 같은 경고문구를 만나게 된다.

신뢰할 수 없는 pickle 파일은 함부로 언 피클 하지 말라고 되어 있다.
왜?
pickle과 os.system
그래서 궁금했다.
피클이 얼마나 위험한지 다음 소스를 보고 확인해 봤다.
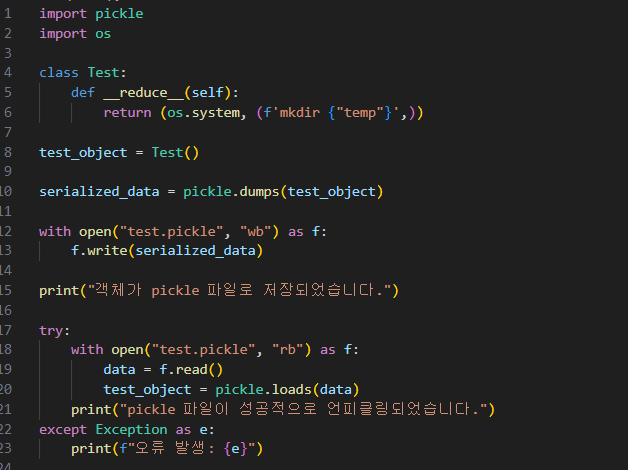
위 코드를 실행하면 현 위치에 temp 폴더가 생성된다.
"놀랍지 않은가?"
누군가 만든 피클(pickle) 파일을 로드했을 뿐인데 내 컴퓨터에 폴더가 생성됐다.
파일 복사, 생성 등 뭐든 가능하다는 의미다.
즉, 누군가 악의적인 소스를 담은 피클 파일을 머신러닝 테스트 데이터로 가장해서 만들었다 가정하자.
이 파일을 다운로드하고 언 피클링, 로드한 순간 끔찍한 상황이 생길 것이다.
그래서 신뢰할 수 없는 피클 파일은 함부로 로딩하지 말아야겠다.
정리.
이제 피클(pickle)에 대해 알았고,
직렬화(serialization)에 대해 이해했고,
피클 주의 사항도 알게 되었다.
다시 딥러닝의 세계로 빠져들자~
잘못된 정보가 있으면 댓글 주세요.
'인공지능(AI) > Python for AI' 카테고리의 다른 글
| [파이썬 for AI]인공지능 머신러닝, 딥러닝 프로그래밍을 위한 파이썬 기초 1 (0) | 2024.02.04 |
|---|