안녕하세요. 신기한 연구소입니다.
어려운 정규표현식 하나씩 쉽게 설명해보겠습니다.

다양한 기법이 있지만 먼저 자바스크립트 정규표현식 중 문자 클래스(Character classes)에 대해
예제를 통해 쉽게 접근해보겠습니다.
코딩할 준비되셨나요?
문자 클래스(Character classes)
서로 다른 종류의 문자(영문자, 숫자 등)를 구별할 수 있습니다.
문자 또는 문자열과 일치하는 패턴을 만들 때 사용합니다.
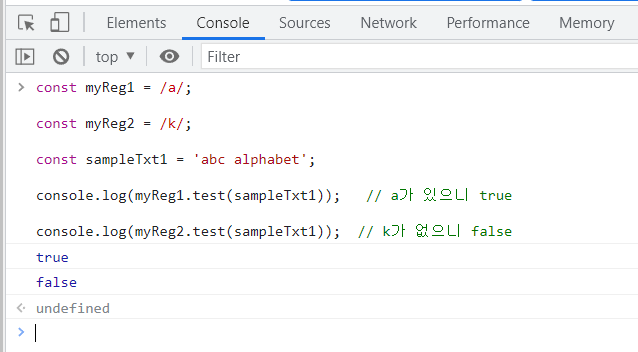
정확히 문자와 일치하는 패턴은 /(슬래시)를 사용했습니다.
/az/는 정확히 문자열 내에서 az를 찾는다는 패턴입니다.
문자 클래스(Character classes)는 대괄호[]를 사용합니다.
대괄호 안의 문자 하나하나를 각각 인식하는 개념입니다.
[az]는 a 또는 z와 일치하는 패턴입니다.
문자 클래스(Character classes)는 하이픈(-)을 사용해서 범위도 지정할 수 있습니다.
[a-z]처럼 코딩하면 a부터 z까지 범위를 패턴으로 정했다는 의미입니다.
설명보단 예제를 통해서 코딩을 직접 하는 것이 더 이해가 빠릅니다.
대괄호 사용.
a 또는 t 또는 z와 일치하는 패턴을 정했습니다.
|
1
2
3
4
5
6
7
8
|
let pattn1 = /[atz]/;
const txt1 = 'He is a teacher';
console.log(txt1.match(pattn1));
console.log(pattn1.exec(txt1));
//결과
(1) ['a', index: 6, input: 'He is a teacher', groups: undefined]
(1) ['a', index: 6, input: 'He is a teacher', groups: undefined]
|
cs |
3개의 문자(atz)중 가장 먼저 만나는 문자는 a이고 위치(index)는 6번째입니다.
위 예제는 예제 문자열 txt1에 match메서드를 패턴을 인자로 넘겨 사용하는 것과
RegExp 내장 함수인 exec를 사용하는 두 가지 예를 보였습니다.
둘 중 어떤 것을 사용해도 괜찮습니다.
|
1
2
3
4
5
6
|
pattn1 = /[atzH]/;
const txt1 = 'He is a teacher';
console.log(txt1.match(pattn1));
//결과
[ 'H', index: 0, input: 'He is a teacher', groups: undefined ]
|
cs |
대소문자를 구분하기에 예문의 He에서 H와 매칭 하고 싶다면
패턴에 H가 포함돼야 합니다.
|
1
2
3
4
5
6
|
let pattn2 = /[a-t]/;
const txt2 = '-He is a teacher';
console.log(pattn2.exec(txt2));
//결과
[ 'e', index: 2, input: '-He is a teacher', groups: undefined ]
|
cs |
대괄호 내 하이픈(-)은 범위를 나타냅니다.
위 패턴은 [abcdefghijklmnopqrst]와 일치합니다. a부터 t까지 입니다.
중요한 것은 He 앞에 특수문자 하이픈(-)이 있지만 인식되지 않습니다.
|
1
2
3
4
5
6
7
|
let pattn4 = /[a-e-]/;
const txt3 = '-He is a teacher';
console.log(pattn4.exec(txt3));
//결과
[ '-', index: 0, input: '-He is a teacher', groups: undefined ]
|
cs |
패턴에 하이픈(-)이 두 개 있습니다.
첫 번째 a-e는 범위를 나타내는 하이픈이고 두 번째 e다음 하이픈(-)이
특수문자 하이픈을 글자 그대로 인식하는 패턴입니다.
[-a] 또는 [a-]처럼 하이픈을 문자 그대로 인식하고 싶으면 대괄호 패턴
제일 앞 또는 뒤에 붙이면 됩니다.
또 다른 특징은 뒤에 하이픈을 붙였지만 가장 먼저 인식을 합니다.
|
1
2
3
4
5
6
7
8
9
10
|
let pattn5 = /[^a-t]/;
let pattn6 = /[^ab-]/;
const txt4 = '-He is a teacher';
console.log(pattn5.exec(txt3));
console.log(pattn6.exec(txt3));
//결과
['-', index: 0, input: '-He is a teacher', groups: undefined]
['H', index: 1, input: '-He is a teacher', groups: undefined]
|
cs |
대괄호 패턴 내 ^를 붙이면 not과 같은 의미입니다.
패턴과 일치하지 않은 반대 패턴을 전부 해당됩니다.
txt4에서 [a-t]의 ^(not)이면 특수문자 하이픈을 가장 먼저 찾습니다.
[^ab-]는 특수문자 하이픈과 a, b를 제외한 패턴입니다.
그렇다면 제일 먼저 만나는 대문자 H가 대상이 됩니다.
|
1
2
3
4
|
let pattn12 = /.a/; //두자리 문자인데 제외문자 외 어떤 문자 + a와 일치
pattn12 = /a.z/; //세자리 문자인데 가운데는 제외문자 외 어떤문자가 올 수 있음.
pattn12 = /..d./; //4글자로 점 3개는 제외문자 외 어떤 문자든 옴.
pattn12 = /..d./; //4글자로 점 3개는 제외문자 외 어떤 문자든 옴.
|
cs |
점은 문자 1개와 일치합니다.
라인 종결자인 \n, \r, \u2028, \u2029는 제외됩니다.
/.t/는 at, it 처럼 점에 글자 하나 넣고 마지막은 t와 일치하는 총 2글자인 패턴과 일치합니다.
하지만 not과는 일치하지 않습니다. 왜냐하면 점이 하나이기 때문에 한 글자만 와야 합니다.
not은 t 빼고 no 두 개의 글자라 일치하지 않습니다.
|
1
2
3
4
5
6
7
8
9
10
11
|
let txt14 = 'We have 8 apples.';
let pattn14 = /\d/;
console.log(pattn14.exec(txt14));
pattn14 = /[0-9]/;
console.log(pattn14.exec(txt14));
//결과
[ '8', index: 8, input: 'We have 8 apples.', groups: undefined ]
[ '8', index: 8, input: 'We have 8 apples.', groups: undefined ]
|
cs |
\d는 모든 숫자(아라비아 숫자)와 일치합니다.
[0-9] 패턴과 동일한 결과를 보입니다.
위 결과를 보면 숫자 8을 매칭 합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
let txt16 = 'We have 5 apples.';
let pattn16 = /\w/;
console.log(txt16.match(pattn16));
txt16 = '#19';
console.log(txt16.match(pattn16));
txt16 = '白3';
console.log(txt16.match(pattn16));
pattn16 = /[A-Za-z0-9_]/;
console.log(txt16.match(pattn16));
//결과
[ 'W', index: 0, input: 'We have 5 apples.', groups: undefined ]
[ '1', index: 1, input: '#19', groups: undefined ]
[ '3', index: 1, input: '白3', groups: undefined ]
[ '3', index: 1, input: '白3', groups: undefined ]
|
cs |
/w는 영문자, 숫자 그리고 언더바(_)와 일치합니다.
[A-Za-z0-9_] 와 동일한 패턴입니다.
|
1
2
3
4
5
6
7
8
9
10
|
let txt18 = 'We have 5 apples.';
let pattn18 = /\s/;
console.log(txt18.match(pattn18));
pattn18 = /\s\w/;
console.log(txt18.match(pattn18));
//결과
[ ' ', index: 2, input: 'We have 5 apples.', groups: undefined ]
[ ' h', index: 2, input: 'We have 5 apples.', groups: undefined ]
|
cs |
\s는 공백, 탭, 폼피드, 라인피드 그리고 기타 유니코드 공백을 포함해서
모든 하나의 공백 문자와 일치합니다.
위 예제를 보면 공백을 잘 찾습니다. space의 약자인 듯합니다.
|
1
2
3
4
5
6
|
let txt20 = 'We have 5 app\tles.';
let pattn20 = /\t/;
console.log(pattn20.exec(txt20));
//결과
[ '\t', index: 13, input: 'We have 5 app\tles.', groups: undefined ]
|
cs |
탭을 패턴으로 정할 때는 \t를 사용합니다.
|
1
2
3
4
5
6
7
8
9
10
11
|
let txt21 = 'We have 5 app\r\nles.';
console.log(txt21);
let pattn21 = /\r/;
console.log(pattn21.exec(txt21));
pattn22 = /\n/;
console.log(pattn22.exec(txt21));
//결과
[ '\r', index: 13, input: 'We have 5 app\r\nles.', groups: undefined ]
[ '\n', index: 14, input: 'We have 5 app\r\nles.', groups: undefined ]
|
cs |
캐리지 리턴과 라인 피트와 일치합니다.
|
1
2
3
4
5
6
7
8
9
10
11
|
let txt23 = 'apples';
let pattn23 = /\ba.....\b/;
console.log(pattn23.exec(txt23));
pattn23 = /\B./;
console.log(pattn23.exec(txt23));
//결과
[ 'apples', index: 0, input: 'apples', groups: undefined ]
[ 'p', index: 1, input: 'apples', groups: undefined ]
|
cs |
/b는 단어의 시작과 끝을 표시합니다.
예를 들어 'We are the world' 문장이 있으면/b는
(We) (are) (the) (world) 처럼 ()의 위치를 매칭 합니다.
\B는 W()e a()r()e t()h()e w()o()r()l()d 처럼 단어 안쪽의 글자 범위를 나타냅니다.
/b 또는 /B 는 위에서 () 을 매칭 합니다.
|
1
2
3
4
5
6
7
8
9
10
11
|
let txt23 = 'cass is beer';
let pattn23 = /.s/;
console.log(pattn23.exec(txt23));
pattn23 = /\b.s\b/;
console.log(pattn23.exec(txt23));
//결과
[ 'ss', index: 2, input: 'cass is beer', groups: undefined ]
[ 'is', index: 5, input: 'cass is beer', groups: undefined ]
|
cs |
만약 is를 찾고 싶은데 /.s/를 패턴으로 실행하면 가장 먼저 만나는 cass의 ss가 출력됩니다.
두 글자 s로 끝나는 단어를 특정한다면
/b를 사용해서 /\b.s\b/ 를 사용하면 범위로 지정하기 때문에 is가 출력됩니다.
이번 포스팅은 문자 클래스, 캐릭터 클래스, Character classes에 대해 알아봤습니다.
간단한 코딩 예제를 사용해서 이해도를 높여봤습니다.
즐 코딩하세요.
'Software > JavaScript' 카테고리의 다른 글
| [자바스크립트]정규표현식 Quantifiers, 수량자 정규식 (0) | 2023.01.08 |
|---|---|
| [자바스크립트]정규표현식 어썰션, Assertions (0) | 2022.12.24 |
| [자바스크립트]정규표현식 만드는 방법, 정규식, regular expression (0) | 2022.11.28 |
| [자바스크립트]프로토타입(prototype)은 무엇인가요? __proto__, [[Prototype]] (0) | 2022.11.20 |
| [자바스크립트]객체 만드는 방법, 생성자 (Object, constructor) (0) | 2022.11.06 |